50 Repositories
Rust llm-inference Libraries

The fastest CLI tool for prompting LLMs. Including support for prompting several LLMs at once!
cai - The fastest CLI tool for prompting LLMs Features Build with Rust 🦀 for supreme performance and speed! 🏎️ Support for models by Groq, OpenAI, A
 45 Jul 21, 2024
45 Jul 21, 2024
Infer a JSON schema from example data, produce nonsense synthetic data (drivel) according to the schema
drivel drivel is a command-line tool written in Rust for inferring a schema from an example JSON (or JSON lines) file, and generating synthetic data (
 36 Jul 5, 2024
36 Jul 5, 2024
Evaluate LLM-generated COBOL
COBOLEval: LLM Evaluation for COBOL COBOLEval is a dataset to evaluate the code generation abilities of Large Language Models on the COBOL programming
 22 Jun 26, 2024
22 Jun 26, 2024
A Rust LLaMA project to load, serve and extend LLM models
OpenLLaMA Overview A Rust LLaMA project to load, serve and extend LLM models. Key Objectives Support both GGML and HF(HuggingFace) models Support a st
 4 Apr 9, 2024
4 Apr 9, 2024

Cloud Native Buildpack that builds an OCI image with Ollama and a large language model.
Ollama Cloud Native Buildpack This buildpack builds an OCI image with Ollama and a large language model. Configure your model by an Ollama Modelfile o
 3 Mar 19, 2024
3 Mar 19, 2024
nl-sh: Natural Language Shell
The Natural Language Shell integrates GPT4 or local GGUF-formatted models directly into the terminal experience, allowing operators to describe their tasks in either POSIX commands or fluent human language
 30 Mar 12, 2024
30 Mar 12, 2024
An egui app for prompting a local offline LLM.
An egui app for prompting a local offline LLM. Description coze is a small egui application for prompting a local offline LLM using the Huggingface ca
 23 Mar 9, 2024
23 Mar 9, 2024
Rust library for integrating local LLMs (with llama.cpp) and external LLM APIs.
Table of Contents About The Project Getting Started Roadmap Contributing License Contact A rust interface for the OpenAI API and Llama.cpp ./server AP
 4 Dec 18, 2023
4 Dec 18, 2023
Putting a brain behind `cat`🐈⬛ Integrating language models in the Unix commands ecosystem through text streams.
smartcat (sc) Puts a brain behind cat! CLI interface to bring language models in the Unix ecosystem and allow power users to make the most out of llms
 28 Dec 2, 2023
28 Dec 2, 2023

Terminal UI to chat with large language models (LLM) using different model backends, and integrations with your favourite editors!
Oatmeal Terminal UI to chat with large language models (LLM) using different model backends, and integrations with your favourite editors! Overview In
 88 Dec 4, 2023
88 Dec 4, 2023
Efficent platform for inference and serving local LLMs including an OpenAI compatible API server.
candle-vllm Efficient platform for inference and serving local LLMs including an OpenAI compatible API server. Features OpenAI compatible API server p
 21 Nov 15, 2023
21 Nov 15, 2023

A single-binary, GPU-accelerated LLM server (HTTP and WebSocket API) written in Rust
Poly Poly is a versatile LLM serving back-end. What it offers: High-performance, efficient and reliable serving of multiple local LLM models Optional
 13 Nov 5, 2023
13 Nov 5, 2023

Slack chat bot written in Rust that allows the user to interact with a large language model.
A Slack chat bot written in Rust that allows the user to interact with a large language model. Creating an App on Slack, first steps Go to https://api
 13 Nov 2, 2023
13 Nov 2, 2023
An LLM-powered (CodeLlama or OpenAI) local diff code review tool.
augre An LLM-powered (CodeLlama or OpenAI) local diff code review tool. Binary Usage Install Windows: $ iwr https://github.com/twitchax/augre/releases
 4 Oct 19, 2023
4 Oct 19, 2023
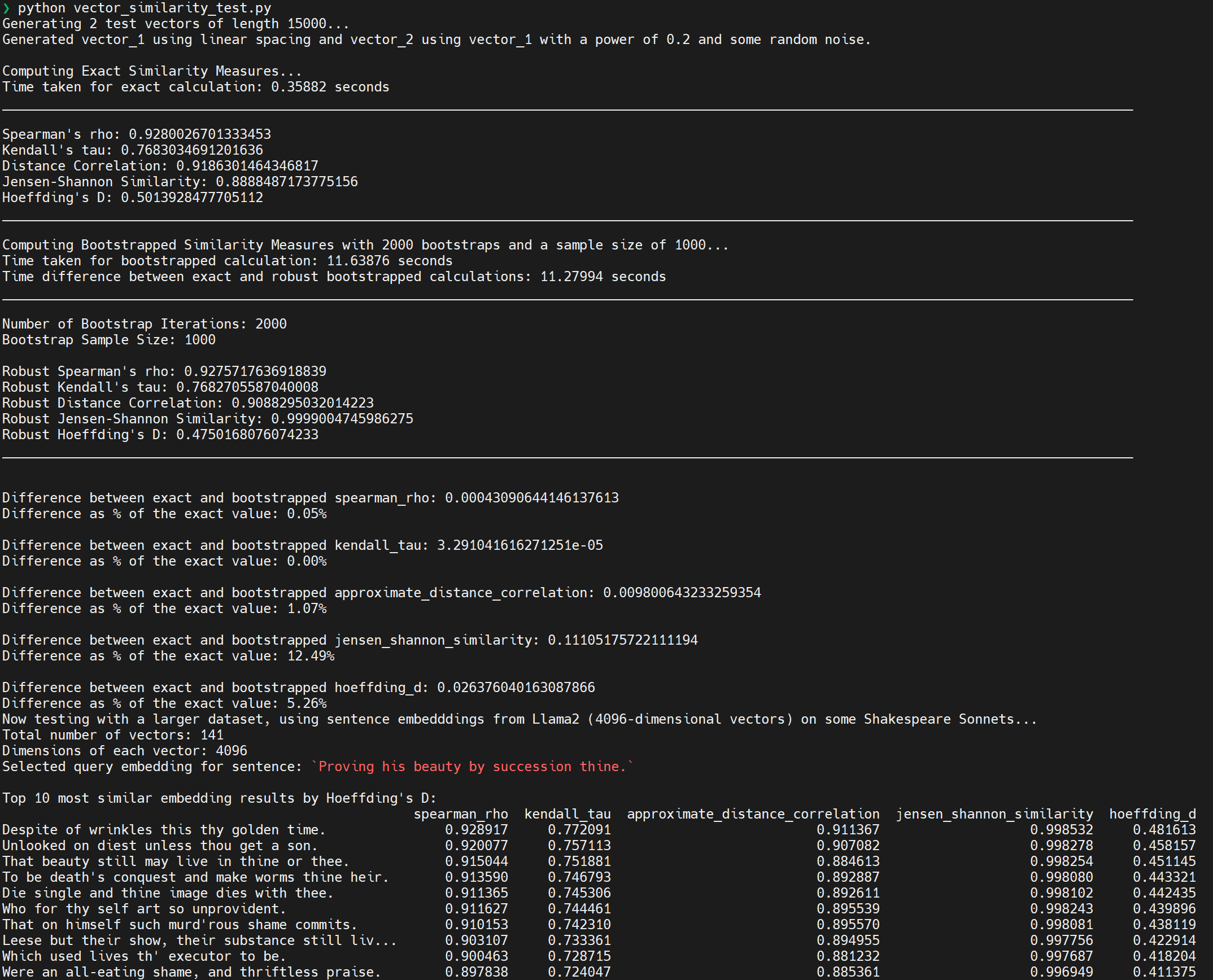
The Fast Vector Similarity Library is designed to provide efficient computation of various similarity measures between vectors.
Fast Vector Similarity Library Introduction The Fast Vector Similarity Library is designed to provide efficient computation of various similarity meas
 243 Sep 6, 2023
243 Sep 6, 2023
LLaMA2 port for Rust inspired by llama2.c
llama2-rs LLaMA2 port for Rust inspired by llama2.c. TODOs: Implement loading of the model Implement forward pass Implement generation Implement token
 4 Aug 27, 2023
4 Aug 27, 2023
Attempt to summarize text from `stdin`, using a large language model (locally and offline), to `stdout`
summarize-cli Attempt to summarize text from stdin, using a large language model (locally and offline), to stdout. cargo build --release target/releas
 4 Aug 23, 2023
4 Aug 23, 2023

A localized open-source AI server that is better than ChatGPT.
💯AI00 RWKV Server English | 中文 | 日本語 AI00 RWKV Server is an inference API server based on the RWKV model. It supports VULKAN inference acceleration a
 142 Aug 23, 2023
142 Aug 23, 2023
Solving context limits when working with AI LLM models by implementing a "chunkable" attribute on your prompt structs.
Promptize Promptize attempts to solve the issues with context limits when working with AI systems. It allows a user to add an attribute to their struc
 5 Jul 18, 2023
5 Jul 18, 2023
The simplest implementation of LLM-backed vector search on Postgres.
pg_vectorize under development The simplest implementation of LLM-backed vector search on Postgres. -- initialize an existing table select vectorize.i
 5 Jul 25, 2023
5 Jul 25, 2023

Super-simple, fully Rust powered "memory" (doc store + semantic search) for LLM projects, semantic search, etc.
memex Super simple "memory" for LLM projects, semantic search, etc. Running the service Note that if you're running on Apple silicon (M1/M2/etc.), it'
 15 Jun 19, 2023
15 Jun 19, 2023

Bring the power of pre-signed URLs to your apps. Signway is a gateway for redirecting authentic signed URLs to the requested API
A gateway that proxies signed requests to other APIs. Check the docs for more info. If you are looking for the managed version checkout this link http
 37 Jun 24, 2023
37 Jun 24, 2023
`dfx new --type=rust` + burn-rs MNIST web inference example
ic-mnist The frontend provides a canvas where users can draw a digit. The drawn digit is then sent to the backend canister running burn-rs for inferen
 4 Jun 25, 2023
4 Jun 25, 2023

Multi-platform desktop app to download and run Large Language Models(LLM) locally in your computer.
Multi-platform desktop app to download and run Large Language Models(LLM) locally in your computer 🔗 Download | Give it a Star ⭐ | Share it on Twitte
 73 Jun 15, 2023
73 Jun 15, 2023

auto-rust is an experimental project that aims to automatically generate Rust code with LLM (Large Language Models) during compilation, utilizing procedural macros.
Auto Rust auto-rust is an experimental project that aims to automatically generate Rust code with LLM (Large Language Models) during compilation, util
 6 May 14, 2023
6 May 14, 2023
Unofficial python bindings for the rust llm library. 🐍❤️🦀
llm-rs-python: Python Bindings for Rust's llm Library Welcome to llm-rs, an unofficial Python interface for the Rust-based llm library, made possible
 7 May 20, 2023
7 May 20, 2023
LLM-chain Rust Template Repository
Jumpstart your llm-chain projects with the llm-chain-template repository! This template provides a foundation for using the llm-chain library, complete with example code and instructions to get you started effortlessly.
 3 May 5, 2023
3 May 5, 2023
LLaMa 7b with CUDA acceleration implemented in rust. Minimal GPU memory needed!
LLaMa 7b in rust This repo contains the popular LLaMa 7b language model, fully implemented in the rust programming language! Uses dfdx tensors and CUD
 16 May 8, 2023
16 May 8, 2023

🚧 WIP 🚧 Vector database plugin for Postgres, written in Rust, specifically designed for LLM.
pgvecto.rs pgvecto.rs is a Postgres extension that provides vector similarity search functions. It is written in Rust and based on pgrx. Features cosi
 74 Apr 26, 2023
74 Apr 26, 2023
TUI interface for LLMs written in Rust 🔥
Tenere TUI interface for LLMs written in Rust 📸 Demo 💎 Supported LLMs Only ChatGPT is supported for the moment. But I'm planning to support more mod
 22 Apr 22, 2023
22 Apr 22, 2023
A program that provides LLMs with the ability to complete complex tasks using plugins.
SmartGPT SmartGPT is an experimental program meant to provide LLMs (particularly GPT-3.5 and GPT-4) with the ability to complete complex tasks without
 8 Apr 19, 2023
8 Apr 19, 2023
Run LLaMA inference on CPU, with Rust 🦀🚀🦙
LLaMA-rs Do the LLaMA thing, but now in Rust 🦀 🚀 🦙 Image by @darthdeus, using Stable Diffusion LLaMA-rs is a Rust port of the llama.cpp project. Th
 2.7k Apr 17, 2023
2.7k Apr 17, 2023

Rust+OpenCL+AVX2 implementation of LLaMA inference code
RLLaMA RLLaMA is a pure Rust implementation of LLaMA large language model inference.. Supported features Uses either f16 and f32 weights. LLaMA-7B, LL
 344 Apr 16, 2023
344 Apr 16, 2023
Run LLaMA inference on CPU, with Rust 🦀🚀🦙
LLaMA-rs Do the LLaMA thing, but now in Rust 🦀 🚀 🦙 Image by @darthdeus, using Stable Diffusion LLaMA-rs is a Rust port of the llama.cpp project. Th
2.7k Apr 17, 2023

Believe in AI democratization. llama for nodejs backed by llama-rs, work locally on your laptop CPU. support llama/alpaca model.
llama-node Large Language Model LLaMA on node.js This project is in an early stage, the API for nodejs may change in the future, use it with caution.
 145 Apr 10, 2023
145 Apr 10, 2023
A small, basical and unoptimized version of RWKV in Rust written by someone with no math or ML knowledge.
Smol Rust RWKV What is it? A simple example of the RWKV approach to language models written in Rust by someone that knows basically nothing about math
 32 Apr 9, 2023
32 Apr 9, 2023
`llm-chain` is a powerful rust crate for building chains in large language models allowing you to summarise text and complete complex tasks
llm-chain 🚀 llm-chain is a collection of Rust crates designed to help you work with Large Language Models (LLMs) more effectively. Our primary focus
36 Apr 6, 2023
A natural language shell interface for *nix systems
Orphic A natural language shell interface for *nix systems. Overview Orphic is a CLI tool that uses GPT to translate complex tasks into shell commands
 42 Mar 29, 2023
42 Mar 29, 2023
pyke Diffusers is a modular Rust library for optimized Stable Diffusion inference 🔮
pyke Diffusers is a modular Rust library for pretrained diffusion model inference to generate images, videos, or audio, using ONNX Runtime as a backen
 12 Jan 5, 2023
12 Jan 5, 2023
Using OpenAI Codex's "davinci-edit" Model for Gradual Type Inference
OpenTau: Using OpenAI Codex for Gradual Type Inference Current implementation is focused on TypeScript Python implementation comes next Requirements r
 11 Dec 18, 2022
11 Dec 18, 2022
A statically-typed, interpreted programming language, with generics and type inference
Glide A programming language. Currently, this includes: Static typing Generics, with monomorphization Type inference on function calls func identityT
 1 Apr 10, 2022
1 Apr 10, 2022
Wonnx - a GPU-accelerated ONNX inference run-time written 100% in Rust, ready for the web
Wonnx is a GPU-accelerated ONNX inference run-time written 100% in Rust, ready for the web. Supported Platforms (enabled by wgpu) API Windows Linux &
 354 Jan 6, 2023
354 Jan 6, 2023
An implementation of a predicative polymorphic language with bidirectional type inference and algebraic data types
Vinilla Lang Vanilla is a pure functional programming language based on System F, a classic but powerful type system. Merits Simple as it is, Vanilla
 73 Aug 4, 2022
73 Aug 4, 2022
A fusion of OTP lib/dialyzer + lib/compiler for regular Erlang with type inference
Typed ERLC The Problem I have a dream, that one day there will be an Erlang compiler, which will generate high quality type-correct code from deduced
 35 Sep 5, 2022
35 Sep 5, 2022
Tiny, no-nonsense, self-contained, Tensorflow and ONNX inference
Sonos' Neural Network inference engine. This project used to be called tfdeploy, or Tensorflow-deploy-rust. What ? tract is a Neural Network inference
 1.5k Jan 2, 2023
1.5k Jan 2, 2023
Orkhon: ML Inference Framework and Server Runtime
Orkhon: ML Inference Framework and Server Runtime Latest Release License Build Status Downloads Gitter What is it? Orkhon is Rust framework for Machin
 129 Dec 21, 2022
129 Dec 21, 2022
Snips NLU rust implementation
Snips NLU Rust Installation Add it to your Cargo.toml: [dependencies] snips-nlu-lib = { git = "https://github.com/snipsco/snips-nlu-rs", branch = "mas
 327 Dec 26, 2022
327 Dec 26, 2022
Orkhon: ML Inference Framework and Server Runtime
Orkhon: ML Inference Framework and Server Runtime Latest Release License Build Status Downloads Gitter What is it? Orkhon is Rust framework for Machin
129 Dec 21, 2022
Tiny, no-nonsense, self-contained, Tensorflow and ONNX inference
Sonos' Neural Network inference engine. This project used to be called tfdeploy, or Tensorflow-deploy-rust. What ? tract is a Neural Network inference
1.5k Jan 8, 2023
A static, type inferred and embeddable language written in Rust.
gluon Gluon is a small, statically-typed, functional programming language designed for application embedding. Features Statically-typed - Static typin
 2.7k Dec 29, 2022
2.7k Dec 29, 2022