Fast Vector Similarity Library
Introduction
The Fast Vector Similarity Library is designed to provide efficient computation of various similarity measures between vectors. It is suitable for tasks such as data analysis, machine learning, and statistics, where measuring the relationship between vectors is essential. Written in Rust, the library offers a high-performance solution and can be easily integrated with Python through provided bindings.
Features
Similarity Measures
The library implements several popular similarity measures, including:
- Spearman's Rank-Order Correlation (
spearman_rho) - Kendall's Tau Rank Correlation (
kendall_tau) - Approximate Distance Correlation (
approximate_distance_correlation) - Jensen-Shannon Similarity (
jensen_shannon_similarity) - Hoeffding's D Measure (
hoeffding_d)
Bootstrapping Technique
The library supports bootstrapping for robust similarity computation. This technique involves randomly resampling the dataset to estimate the distribution of the similarity measures, providing more confidence in the results.
Performance Optimizations
To achieve high efficiency, the library leverages:
- Parallel Computing: Using the
rayoncrate, computations are parallelized across available CPU cores. - Vectorized Operations: The library leverages efficient vectorized operations provided by the
ndarraycrate.
Python Bindings
The library includes Python bindings to enable seamless integration with Python code. Functions py_compute_vector_similarity_stats and py_compute_bootstrapped_similarity_stats are exposed, allowing you to compute similarity statistics and bootstrapped similarity statistics, respectively.
Installation
Rust
Include the library in your Rust project by adding it to your Cargo.toml file.
Python
You can install the Python bindings for the Fast Vector Similarity Library directly from PyPI using the following command:
pip install fast_vector_similarity
This command will download and install the package, making it available for use in your Python projects.
Use with Text Embedding Vectors from LLMs
The Python demo code below introduces additional functionality that allows the Fast Vector Similarity Library to easily work with text embedding vectors from Language Models like LLMs (e.g., Llama2), such as those generated by my other library, the Llama2 Embeddings FastAPI Service (particularly, the output of the /get_all_embedding_vectors_for_document endpoint):
1. Converting Text Embeddings to Pandas DataFrame
The function convert_embedding_json_to_pandas_df reads text embeddings from a JSON file and converts them into a Pandas DataFrame. Each embedding is associated with a specific text (e.g., a sentence from Shakespeare's Sonnets), and the DataFrame structure facilitates manipulation and analysis of these embeddings.
2. Applying Fast Vector Similarity to Text Embeddings
The function apply_fvs_to_vector takes a row of embeddings and a query embedding, applies the chosen similarity measures, and returns the results as a JSON object. This function leverages the core similarity computation functionality provided by the Fast Vector Similarity Library, allowing it to be used directly on text embeddings.
3. Comparing Embeddings with Large Datasets
The main section of the code includes an example where text embeddings from Llama2 are loaded and analyzed. This part of the code demonstrates how to:
- Select a random query embedding from the dataset.
- Compute similarity measures between the query embedding and the rest of the dataset.
- Create a DataFrame to hold the similarity results.
- Sort and display the top 10 most similar embeddings by Hoeffding's D.
4. Compatibility with Higher-Dimensional Embeddings
The example works with 4096-dimensional vectors, showcasing the library's ability to handle high-dimensional data typical of modern language models. This compatibility ensures that the library can be used with a wide range of language models and text embedding techniques. In fact, the library can easily handle even larger dimensions.
Example Python Code
import time
import numpy as np
import json
import pandas as pd
from random import choice
import fast_vector_similarity as fvs
def convert_embedding_json_to_pandas_df(file_path):
# Read the JSON file
with open(file_path, 'r') as file:
data = json.load(file)
# Extract the text and embeddings
texts = [item['text'] for item in data]
embeddings = [item['embedding'] for item in data]
# Determine the total number of vectors and the dimensions of each vector
total_vectors = len(embeddings)
vector_dimensions = len(embeddings[0]) if total_vectors > 0 else 0
# Print the total number of vectors and dimensions
print(f"Total number of vectors: {total_vectors}")
print(f"Dimensions of each vector: {vector_dimensions}")
# Convert the embeddings into a DataFrame
df = pd.DataFrame(embeddings, index=texts)
return df
def apply_fvs_to_vector(row_embedding, query_embedding):
params = {
"vector_1": query_embedding.tolist(),
"vector_2": row_embedding.tolist(),
"similarity_measure": "all"
}
similarity_stats_str = fvs.py_compute_vector_similarity_stats(json.dumps(params))
return json.loads(similarity_stats_str)
def main():
length_of_test_vectors = 15000
print(f"Generating 2 test vectors of length {length_of_test_vectors}...")
vector_1 = np.linspace(0., length_of_test_vectors - 1, length_of_test_vectors)
vector_2 = vector_1 ** 0.2 + np.random.rand(length_of_test_vectors)
print("Generated vector_1 using linear spacing and vector_2 using vector_1 with a power of 0.2 and some random noise.\n")
similarity_measure = "all" # Or specify a particular measure
params = {
"vector_1": vector_1.tolist(),
"vector_2": vector_2.tolist(),
"similarity_measure": similarity_measure
}
# Time the exact similarity calculation
print("Computing Exact Similarity Measures...")
start_time_exact = time.time()
similarity_stats_str = fvs.py_compute_vector_similarity_stats(json.dumps(params))
similarity_stats_json = json.loads(similarity_stats_str)
elapsed_time_exact = time.time() - start_time_exact
print(f"Time taken for exact calculation: {elapsed_time_exact:.5f} seconds")
# Print results
print("_______________________________________________________________________________________________________________________________________________\n")
print("Spearman's rho:", similarity_stats_json["spearman_rho"])
print("Kendall's tau:", similarity_stats_json["kendall_tau"])
print("Distance Correlation:", similarity_stats_json["approximate_distance_correlation"])
print("Jensen-Shannon Similarity:", similarity_stats_json["jensen_shannon_similarity"])
print("Hoeffding's D:", similarity_stats_json["hoeffding_d"])
print("_______________________________________________________________________________________________________________________________________________\n")
# Bootstrapped calculations
number_of_bootstraps = 2000
n = 15
sample_size = int(length_of_test_vectors / n)
print(f"Computing Bootstrapped Similarity Measures with {number_of_bootstraps} bootstraps and a sample size of {sample_size}...")
start_time_bootstrapped = time.time()
params_bootstrapped = {
"x": vector_1.tolist(),
"y": vector_2.tolist(),
"sample_size": sample_size,
"number_of_bootstraps": number_of_bootstraps,
"similarity_measure": similarity_measure
}
bootstrapped_similarity_stats_str = fvs.py_compute_bootstrapped_similarity_stats(json.dumps(params_bootstrapped))
bootstrapped_similarity_stats_json = json.loads(bootstrapped_similarity_stats_str)
elapsed_time_bootstrapped = time.time() - start_time_bootstrapped
print(f"Time taken for bootstrapped calculation: {elapsed_time_bootstrapped:.5f} seconds")
time_difference = abs(elapsed_time_exact - elapsed_time_bootstrapped)
print(f"Time difference between exact and robust bootstrapped calculations: {time_difference:.5f} seconds")
# Print bootstrapped results
print("_______________________________________________________________________________________________________________________________________________\n")
print("Number of Bootstrap Iterations:", bootstrapped_similarity_stats_json["number_of_bootstraps"])
print("Bootstrap Sample Size:", bootstrapped_similarity_stats_json["sample_size"])
print("\nRobust Spearman's rho:", bootstrapped_similarity_stats_json["spearman_rho"])
print("Robust Kendall's tau:", bootstrapped_similarity_stats_json["kendall_tau"])
print("Robust Distance Correlation:", bootstrapped_similarity_stats_json["approximate_distance_correlation"])
print("Robust Jensen-Shannon Similarity:", bootstrapped_similarity_stats_json["jensen_shannon_similarity"])
print("Robust Hoeffding's D:", bootstrapped_similarity_stats_json["hoeffding_d"])
print("_______________________________________________________________________________________________________________________________________________\n")
# Compute the differences between exact and bootstrapped results
measures = ["spearman_rho", "kendall_tau", "approximate_distance_correlation", "jensen_shannon_similarity", "hoeffding_d"]
for measure in measures:
exact_value = similarity_stats_json[measure]
bootstrapped_value = bootstrapped_similarity_stats_json[measure]
absolute_difference = abs(exact_value - bootstrapped_value)
percentage_difference = (absolute_difference / exact_value) * 100
print(f"\nDifference between exact and bootstrapped {measure}: {absolute_difference}")
print(f"Difference as % of the exact value: {percentage_difference:.2f}%")
print("Now testing with a larger dataset, using sentence embedddings from Llama2 (4096-dimensional vectors) on some Shakespeare Sonnets...")
# Load the embeddings into a DataFrame
input_file_path = "sample_input_files/Shakespeare_Sonnets_small.json"
embeddings_df = convert_embedding_json_to_pandas_df(input_file_path)
# Select a random row for the query embedding
query_embedding_index = choice(embeddings_df.index)
query_embedding = embeddings_df.loc[query_embedding_index]
print(f"Selected query embedding for sentence: `{query_embedding_index}`")
# Remove the selected row from the DataFrame
embeddings_df = embeddings_df.drop(index=query_embedding_index)
# Apply the function to each row of embeddings_df
json_outputs = embeddings_df.apply(lambda row: apply_fvs_to_vector(row, query_embedding), axis=1)
# Create a DataFrame from the list of JSON outputs
vector_similarity_results_df = pd.DataFrame.from_records(json_outputs)
vector_similarity_results_df.index = embeddings_df.index
# Add the required columns to the DataFrame
columns = ["spearman_rho", "kendall_tau", "approximate_distance_correlation", "jensen_shannon_similarity", "hoeffding_d"]
vector_similarity_results_df = vector_similarity_results_df[columns]
# Sort the DataFrame by the hoeffding_d column in descending order
vector_similarity_results_df = vector_similarity_results_df.sort_values(by="hoeffding_d", ascending=False)
print("\nTop 10 most similar embedding results by Hoeffding's D:")
print(vector_similarity_results_df.head(10))
Screenshot of Output:
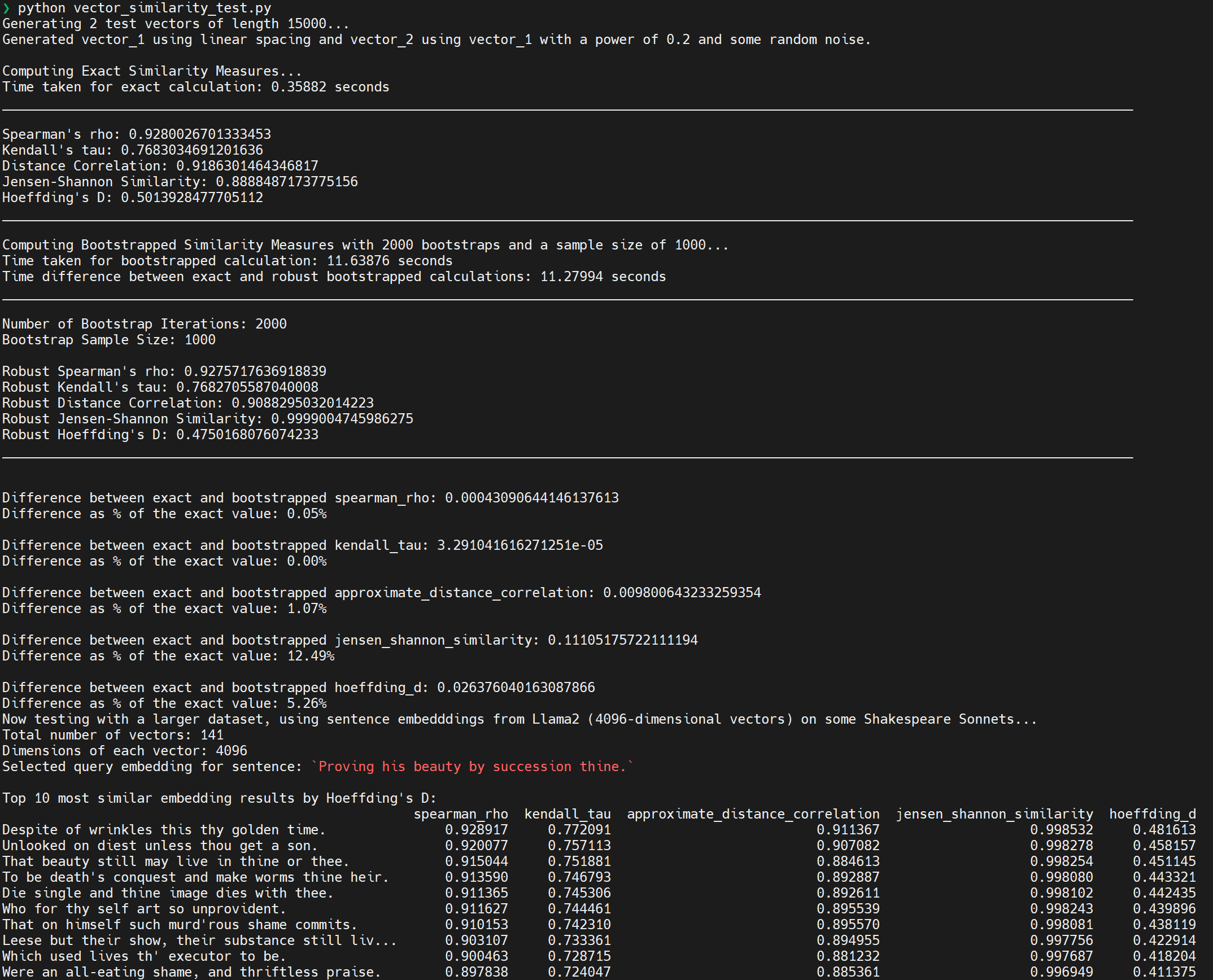
Usage
In Rust
You can utilize the core functionality in Rust by calling functions like compute_vector_similarity_stats and compute_bootstrapped_similarity_stats with appropriate parameters.
In Python
Install the provided Python package and use the functions as demonstrated in the example above.
About the Different Similarity Measures
-
Spearman's Rank-Order Correlation (
spearman_rho): Spearman's rho assesses the strength and direction of the monotonic relationship between two ranked variables. Unlike Pearson's correlation, it does not assume linearity and is less sensitive to outliers, making it suitable for non-linear relationships. -
Kendall's Tau Rank Correlation (
kendall_tau): Kendall's tau measures the ordinal association between two variables. It's valuable for its ability to handle ties and its interpretability as a probability. Unlike other correlation measures, it's based on the difference between concordant and discordant pairs, making it robust and versatile. -
Approximate Distance Correlation (
approximate_distance_correlation): Distance correlation quantifies both linear and non-linear dependencies between variables. It has the powerful property of being zero if and only if the variables are independent. This makes it a more comprehensive measure of association than traditional correlation metrics. -
Jensen-Shannon Similarity (
jensen_shannon_similarity): Jensen-Shannon Similarity is derived from the Jensen-Shannon Divergence, a symmetrical and smoothed version of the Kullback-Leibler divergence. It quantifies the similarity between two probability distributions and is especially useful in comparing distributions that may have non-overlapping support. -
Hoeffding's D Measure (
hoeffding_d): Hoeffding's D is a non-parametric measure that detects complex non-linear relationships between variables. The D statistic is robust against various alternatives to independence, including non-monotonic relationships. It's particularly useful when the nature of the relationship between variables is unknown or unconventional.
Each of these measures has unique properties and applicability, providing a comprehensive toolkit for understanding the relationships between variables in different contexts. By including both classical and more specialized measures, the library offers flexibility and depth in analyzing vector similarities.
Bootstrapping Technique for Robust Estimators
Bootstrapping is a powerful statistical method that allows us to estimate the distribution of a statistic by repeatedly resampling with replacement from the observed data. In the context of the Fast Vector Similarity Library, bootstrapping is employed to obtain robust estimators of similarity measures between vectors. Here's how it works:
Process
-
Random Subset Selection: For each bootstrap iteration, a random subset of indices is selected from the original vectors. These indices are used to create resampled vectors that preserve the original data's structure and relationships.
-
Compute Similarity: The selected random subset of indices is used to compute the similarity between the resampled vectors according to the chosen similarity measure. This process is repeated many times, resulting in a distribution of similarity estimates.
-
Robust Averaging: To obtain a robust estimator that is less sensitive to outliers, the interquartile range (IQR) of the distribution of similarity estimates is considered. By keeping only the values within the IQR, the influence of extreme values is minimized. A robust average of the values within this range provides the final robust similarity estimate.
Why It's Useful
The bootstrapping technique offers several advantages:
-
Robustness to Outliers: By focusing on the interquartile range and using a robust average, bootstrapping minimizes the influence of outliers. This makes the estimator more reliable, especially when the original data may contain anomalous values.
-
Model-Free Estimation: Bootstrapping doesn't assume a specific underlying distribution, making it a non-parametric method. This flexibility allows it to be applied to various types of data and similarity measures.
-
Confidence Intervals: Bootstrapping can also be used to construct confidence intervals for the similarity measures. These intervals provide insights into the uncertainty associated with the estimate, enhancing interpretability.
-
Enhanced Understanding of Relationships: By assessing the distribution of similarity measures, bootstrapping provides a more comprehensive view of the relationships between vectors. This deeper understanding can be vital in contexts like data analysis, where subtle differences in relationships may have significant implications.
The inclusion of the bootstrapping technique in the Fast Vector Similarity Library adds a layer of robustness and flexibility to the computation of similarity measures. It offers users a way to obtain more reliable and insightful estimates, accommodating various data characteristics and analytical needs. Whether dealing with potential outliers or seeking a more nuanced understanding of vector relationships, bootstrapping provides a valuable tool within the library's comprehensive suite of features.

 3 Dec 25, 2023
3 Dec 25, 2023
 21 Apr 23, 2024
21 Apr 23, 2024
 1 Oct 26, 2021
1 Oct 26, 2021
 2 Jan 17, 2022
2 Jan 17, 2022

 5 Jun 4, 2023
5 Jun 4, 2023

 2 Jul 3, 2023
2 Jul 3, 2023
 1 Feb 4, 2022
1 Feb 4, 2022
 20 Dec 26, 2022
20 Dec 26, 2022
 7 Jan 10, 2023
7 Jan 10, 2023


 8 Feb 1, 2023
8 Feb 1, 2023
 4 Oct 13, 2023
4 Oct 13, 2023
 2 May 16, 2022
2 May 16, 2022
 5 Mar 17, 2023
5 Mar 17, 2023
 4 Mar 28, 2022
4 Mar 28, 2022
 7 Dec 3, 2022
7 Dec 3, 2022
 78 Apr 18, 2023
78 Apr 18, 2023
 8 May 21, 2023
8 May 21, 2023
 29 Nov 24, 2023
29 Nov 24, 2023