![]()
Vector Similarity Search Engine with extended filtering support
![]()
Qdrant (read: quadrant ) is a vector similarity search engine. It provides a production-ready service with a convenient API to store, search, and manage points - vectors with an additional payload. Qdrant is tailored to extended filtering support. It makes it useful for all sorts of neural-network or semantic-based matching, faceted search, and other applications.
Qdrant is written in Rust
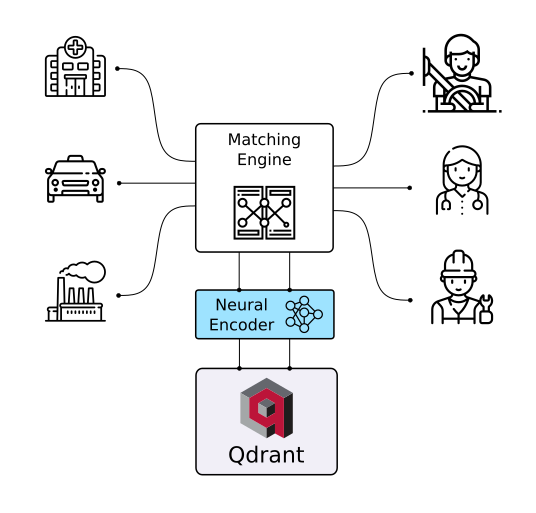
With Qdrant, embeddings or neural network encoders can be turned into full-fledged applications for matching, searching, recommending, and much more!
Demo Projects
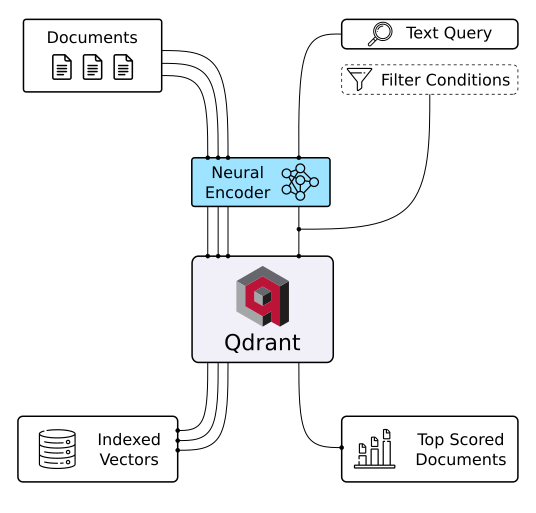
Semantic Text Search
🔍
The neural search uses semantic embeddings instead of keywords and works best with short texts. With Qdrant and a pre-trained neural network, you can build and deploy semantic neural search on your data in minutes. Try it online!
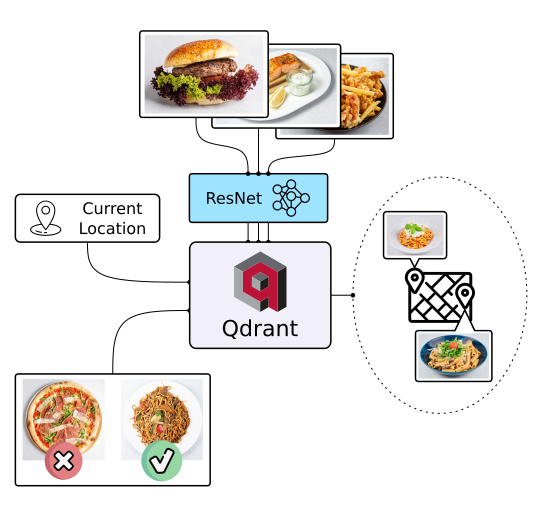
Similar Image Search - Food Discovery
🍕
There are multiple ways to discover things, text search is not the only one. In the case of food, people rely more on appearance than description and ingredients. So why not let people choose their next lunch by its appearance, even if they don’t know the name of the dish? Check it out!
Extreme classification - E-commerce Product Categorization
📺
Extreme classification is a rapidly growing research area within machine learning focusing on multi-class and multi-label problems involving an extremely large number of labels. Sometimes it is millions and tens of millions classes. The most promising way to solve this problem is to use similarity learning models. We put together a demo example of how you could approach the problem with a pre-trained transformer model and Qdrant. So you can play with it online!
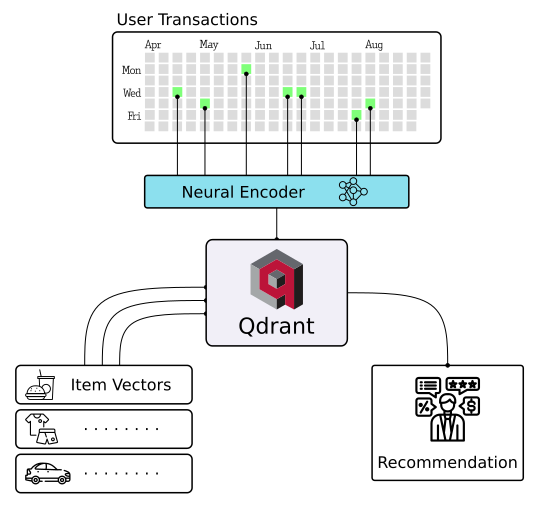
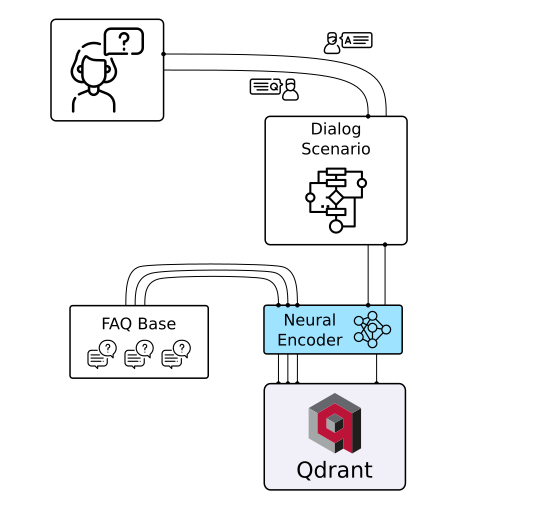
More solutions
 |
 |
 |
| Semantic Text Search | Similar Image Search | Recommendations |
 |
 |
| Chat Bots | Matching Engines |
API
Online OpenAPI 3.0 documentation is available here. OpenAPI makes it easy to generate a client for virtually any framework or programing language.
You can also download raw OpenAPI definitions.
Features
Filtering
Qdrant supports key-value payload associated with vectors. It does not only store payload but also allows filter results based on payload values. It allows any combinations of should, must, and must_not conditions, but unlike ElasticSearch post-filtering, Qdrant guarantees all relevant vectors are retrieved.
Rich data types
Vector payload supports a large variety of data types and query conditions, including string matching, numerical ranges, geo-locations, and more. Payload filtering conditions allow you to build almost any custom business logic that should work on top of similarity matching.
Query planning and payload indexes
Using the information about the stored key-value data, the query planner decides on the best way to execute the query. For example, if the search space limited by filters is small, it is more efficient to use a full brute force than an index.
SIMD Hardware Acceleration
With the BLAS library, Qdrant can take advantage of modern CPU architectures. It allows you to search even faster on modern hardware.
Write-ahead logging
Once the service confirmed an update - it won't lose data even in case of power shut down. All operations are stored in the update journal and the latest database state could be easily reconstructed at any moment.
Stand-alone
Qdrant does not rely on any external database or orchestration controller, which makes it very easy to configure.
Usage
Docker
🐳
Build your own from source
docker build . --tag=qdrant
Or use latest pre-built image from DockerHub
docker pull generall/qdrant
To run container use command:
docker run -p 6333:6333 \
-v $(pwd)/path/to/data:/qdrant/storage \
-v $(pwd)/path/to/custom_config.yaml:/qdrant/config/production.yaml \
qdrant
/qdrant/storage- is a place where Qdrant persists all your data. Make sure to mount it as a volume, otherwise docker will drop it with the container./qdrant/config/production.yaml- is the file with engine configuration. You can override any value from the reference config
Now Qdrant should be accessible at localhost:6333
Docs
📓
- The best place to start is Quick Start Guide
- The Documentation
- Use the OpenAPI specification as a reference
- Follow our Step-by-Step Tutorial to create your first neural network project with Qdrant
Contacts
- Join our Telegram group
- Follow us on Twitter
- Subscribe to our Newsletters
- Write us an email [email protected]
Contributors
✨
Thanks to the people who contributed to Qdrant:
 Andrey Vasnetsov |
 Andre Zayarni |
 Joan Fontanals |
 trean |
 Konstantin |
License
Qdrant is licensed under the Apache License, Version 2.0. View a copy of the License file.





![[Question] is there any doc. to set distributed setup in kubernetes](https://avatars.githubusercontent.com/u/46225496?v=4)





 27 Nov 2, 2022
27 Nov 2, 2022
 0 Sep 15, 2018
0 Sep 15, 2018
 35 Oct 30, 2023
35 Oct 30, 2023
 53 Nov 24, 2022
53 Nov 24, 2022
 6 Oct 21, 2022
6 Oct 21, 2022
 318 Dec 22, 2022
318 Dec 22, 2022
 522 Dec 20, 2022
522 Dec 20, 2022
 74 Apr 26, 2023
74 Apr 26, 2023
 93 Dec 30, 2022
93 Dec 30, 2022
 283 Dec 21, 2022
283 Dec 21, 2022
 2.3k Jan 3, 2023
2.3k Jan 3, 2023
 6 Oct 19, 2022
6 Oct 19, 2022
 2 Apr 1, 2022
2 Apr 1, 2022
 145 Apr 10, 2023
145 Apr 10, 2023
 5 Jun 21, 2023
5 Jun 21, 2023
 982 Dec 31, 2022
982 Dec 31, 2022
 3 Nov 20, 2023
3 Nov 20, 2023
 243 Sep 6, 2023
243 Sep 6, 2023
 71 Dec 28, 2022
71 Dec 28, 2022