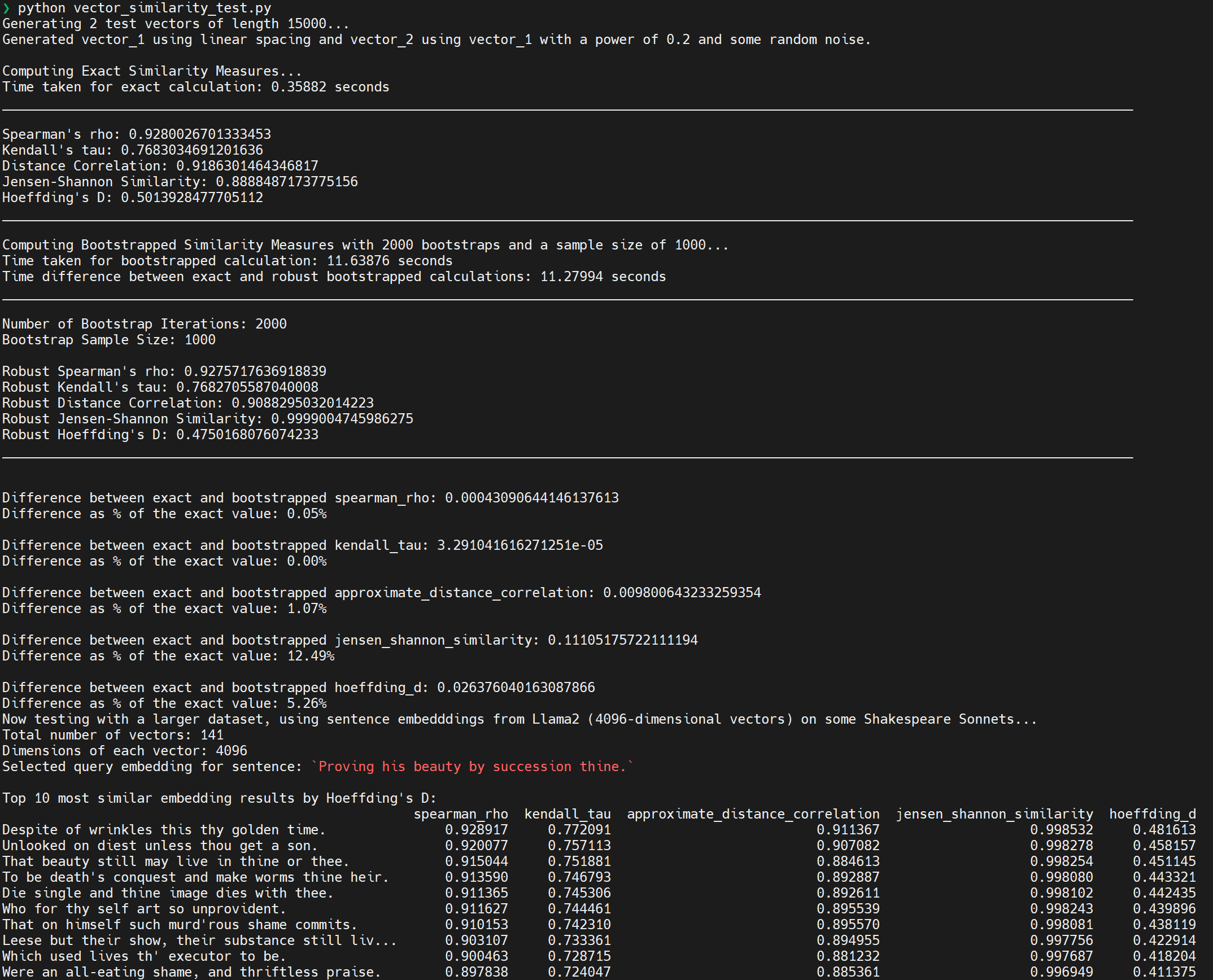
Substring search is one of the most common operations in text processing, and one of the slowest. StringZilla was designed to supersede LibC and implement those core operations in CPU-friendly manner, using branchless operations, SWAR, and SIMD assembly instructions. Notably, Rust has a memchr crate that provides a similar functionality, and it's used in many popular libraries. This repository provides basic benchmarking scripts for comparing the throughput of stringzilla and memchr. For normal order and reverse order search, over ASCII and UTF8 input data, the following numbers can be expected.
| ASCII ⏩ | ASCII ⏪ | UTF8 ⏩ | UTF8 ⏪ | |
|---|---|---|---|---|
| Intel: | ||||
memchr |
5.89 GB/s | 1.08 GB/s | 8.73 GB/s | 3.35 GB/s |
stringzilla |
8.37 GB/s | 8.21 GB/s | 11.21 GB/s | 11.20 GB/s |
| Arm: | ||||
memchr |
6.38 GB/s | 1.12 GB/s | 13.20 GB/s | 3.56 GB/s |
stringzilla |
6.56 GB/s | 5.56 GB/s | 9.41 GB/s | 8.17 GB/s |
| Average | 1.2x faster | 6.2x faster | - | 2.8x faster |
For Intel the benchmark was run on AWS
r7izinstances with Sapphire Rapids cores. For Arm the benchmark was run on AWSr7ginstances with Graviton 3 cores. The ⏩ signifies forward search, and ⏪ signifies reverse order search. At the time of writing, the latest versions ofmemchrandstringzillawere used - 2.7.1 and 3.3.0, respectively.
Before running benchmarks, you can test your Rust environment running:
cargo install cargo-criterion --locked
HAYSTACK_PATH=README.md cargo criterion --jobs 8
As part of the benchmark, the input "haystack" file is whitespace-tokenized into an array of strings. In every benchmark iteration, a new "needle" is taken from that array of tokens. All inclusions of that token in the haystack are counted, and the throughput is calculated. This generally results in very stable and predictable results. The benchmark also includes a warm-up, to ensure that the CPU caches are filled and the results are not affected by cold start or SIMD-related frequency scaling.
For benchmarks on ASCII data I've used the English Leipzig Corpora Collection. It's 124 MB in size, 1'000'000 lines long, and contains 8'388'608 tokens of mean length 5.
wget --no-clobber -O leipzig1M.txt https://introcs.cs.princeton.edu/python/42sort/leipzig1m.txt
HAYSTACK_PATH=leipzig1M.txt cargo criterion --jobs 8
For richer mixed UTF data, I've used the XL Sum dataset for multilingual extractive summarization. It's 4.7 GB in size (1.7 GB compressed), 1'004'598 lines long, and contains 268'435'456 tokens of mean length 8. To download, unpack, and run the benchmarks, execute the following bash script in your terminal:
wget --no-clobber -O xlsum.csv.gz https://github.com/ashvardanian/xl-sum/releases/download/v1.0.0/xlsum.csv.gz
gzip -d xlsum.csv.gz
HAYSTACK_PATH=xlsum.csv cargo criterion --jobs 8
 4 Oct 25, 2022
4 Oct 25, 2022
 243 Sep 6, 2023
243 Sep 6, 2023
 16 Sep 19, 2022
16 Sep 19, 2022

 239 Jan 4, 2023
239 Jan 4, 2023
 657 Dec 30, 2022
657 Dec 30, 2022
 635 Jan 3, 2023
635 Jan 3, 2023
 7 Nov 15, 2022
7 Nov 15, 2022
 561 Dec 26, 2022
561 Dec 26, 2022
 493 Jan 4, 2023
493 Jan 4, 2023

 5 Mar 17, 2023
5 Mar 17, 2023
 15 Jun 19, 2023
15 Jun 19, 2023
 3 Sep 7, 2022
3 Sep 7, 2022
 223 Dec 26, 2022
223 Dec 26, 2022
 3 Apr 10, 2024
3 Apr 10, 2024
 43 Jun 25, 2023
43 Jun 25, 2023
 1 Nov 1, 2021
1 Nov 1, 2021
 1 Feb 4, 2022
1 Feb 4, 2022
 20 Dec 26, 2022
20 Dec 26, 2022
 1 Feb 7, 2022
1 Feb 7, 2022