schema_analysis
Universal-ish Schema Analysis
Ever wished you could figure out what was in that json file? Or maybe it was xml... Ehr, yaml? It was definitely toml.
Alas, many great tools will only work with one of those formats, and the internet is not so nice a place as to finally understand that no, xml is not an acceptable document format.
Enter this neat little tool, a single interface to any self-describing format supported by our gymnast friend, serde.
Features
- Works with any self-describing format with a Serde implementation.
- Suitable for large files.
- Keeps track of some useful info for each type.
- Keeps track of null/normal/missing/duplicate values separately.
- Integrates with Schemars and json_typegen to produce types and json schema if needed.
- There's a demo website here.
Usage
let data: &[u8] = b"true";
// Just pick your format, and deserialize InferredSchema as if it were a normal type.
let inferred: InferredSchema = serde_json::from_slice(data)?;
// let inferred: InferredSchema = serde_yaml::from_slice(data)?;
// let inferred: InferredSchema = serde_cbor::from_slice(data)?;
// let inferred: InferredSchema = toml::from_slice(data)?;
// let inferred: InferredSchema = rawbson::de::from_bytes(data)?;
// let inferred: InferredSchema = quick_xml::de::from_reader(data)?;
// InferredSchema is a wrapper around Schema
let schema: Schema = inferred.schema;
let expected: Schema = Schema::Boolean(Default::default());
assert!(schema.structural_eq(&expected));
// The wrapper is there so we can both do the magic above, and also store the data for later
let serialized_schema: String = serde_json::to_string_pretty(&schema)?;
That's it.
Check Schema to see what info you get, and targets to see the available integrations (which include code and json schema generation).
Advanced Usage
I know, I know, the internet is evil and has decided to plague you with not one, but thousands, maybe even millions, of files.
Unfortunately Serde relies on type information to work, so there is nothing we can do about it we can bring out the big guns: DeserializeSeed. It's everything you love about Serde, but with runtime state.
let a_lot_of_json_files: &[&str] = &[ "1", "2", "1000" ];
let mut iter = a_lot_of_json_files.iter();
if let Some(file) = iter.next() {
// We use the first file to generate a new schema to work with.
let mut inferred: InferredSchema = serde_json::from_str(file)?;
// Then we iterate over the rest to expand the schema.
for file in iter {
let mut json_deserializer = serde_json::Deserializer::from_str(file);
// DeserializeSeed is implemented on &mut InferredSchema
// So here it borrows the data mutably and runs it against the deserializer.
let () = inferred.deserialize(&mut json_deserializer)?;
}
// The result in this case would be a simple integer schema
// that 'has met' the numbers 1, 2, and 100.
let mut context: NumberContext<i128> = Default::default();
context.aggregate(&1);
context.aggregate(&2);
context.aggregate(&1000);
assert_eq!(inferred.schema, Schema::Integer(context));
}
Furthermore, if you need to generate separate schemas (for example to run the analysis on multiple threads) you can use the Coalesce trait to merge them after-the-fact.
I really wish I could convert that Schema in something, you know, actually useful.
You are in luck! You can check out here the integrations with json_typegen and Schemars to convert the analysis into useful files like Rust types and json schemas. You can also find a demo website here.
How does this work?
For a the short story long go here, the juicy bit is that Serde is kind enough to let the format tell us what it is working with, we take it from there and construct a nice schema from that info.
Performance
These are not proper benchmarks, but should give a vague idea of the performance on a 3 years old i7 laptop with the raw data already loaded into memory.
| Size | wasm (MB/s) | native (MB/s) | Format | File # |
|---|---|---|---|---|
| ~180MB | ~20s (9) | ~5s (36) | json | 1 |
| ~650MB | ~150s (4.3) | ~50s (13) | json | 1 |
| ~1.7GB | ~470s (3.6) | ~145s (11.7) | json | 1 |
| ~2.1GB | a | ~182s (11.5) | json | 1 |
| ~13.3GBb | ~810s (16.4) | xml | ~200k |
a This one seems to go over some kind of browser limit when fetching the data in the Web Worker, I believe I would have to split large files to handle it.
b ~2.7GB compressed. This one seems like it would be a worst-case scenario because it includes decompression overhead and the files had a section that was formatted text which resulted in crazy schemas. (The json pretty printed schema was almost 0.5GB!)
 1.5k Jan 7, 2023
1.5k Jan 7, 2023
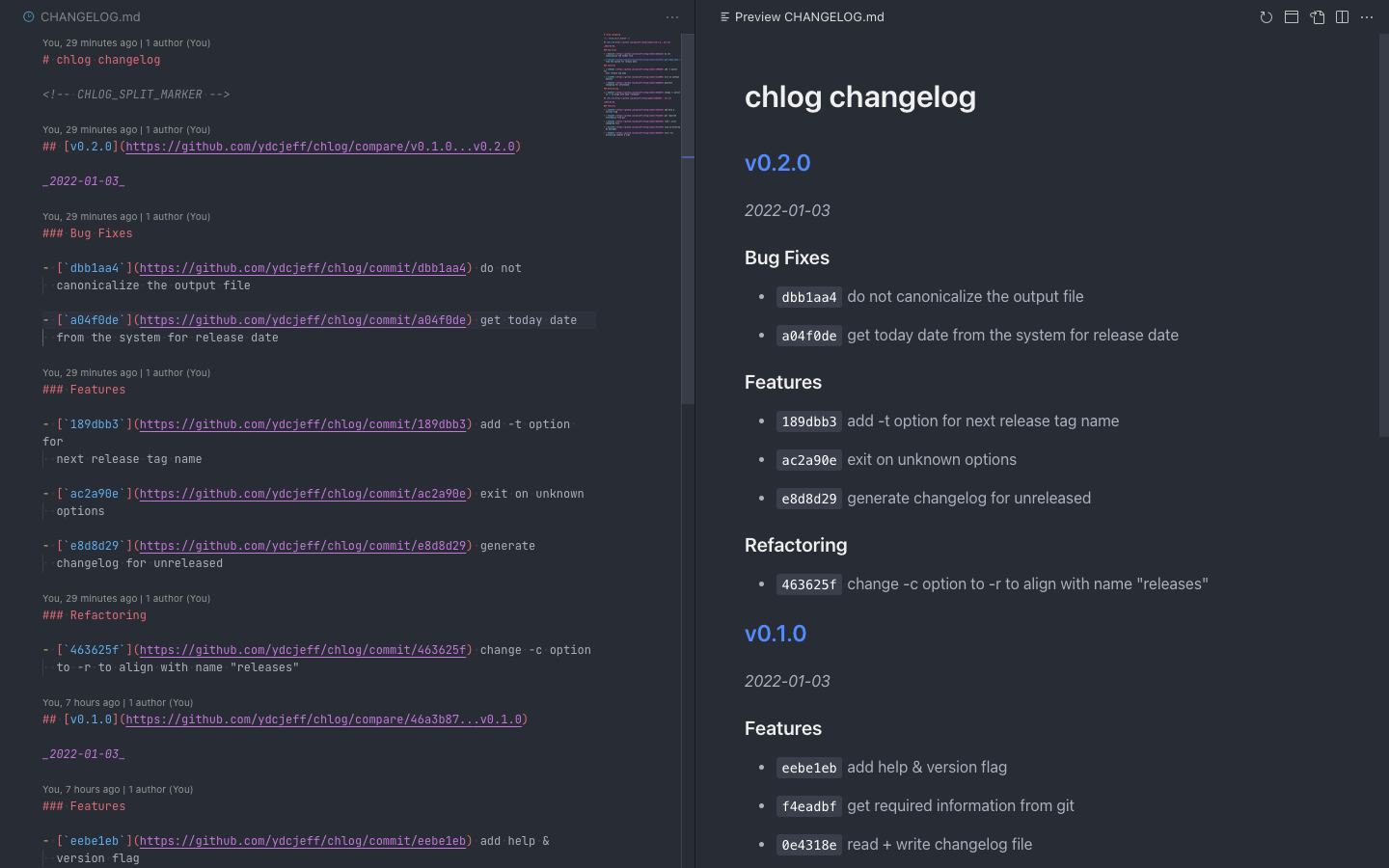
 3 Nov 27, 2022
3 Nov 27, 2022

 7 Dec 21, 2022
7 Dec 21, 2022
 39 Dec 30, 2022
39 Dec 30, 2022

 3 Sep 2, 2022
3 Sep 2, 2022
 6 Sep 11, 2022
6 Sep 11, 2022

 6 Dec 10, 2022
6 Dec 10, 2022
 13 Apr 7, 2023
13 Apr 7, 2023
 29 Oct 9, 2023
29 Oct 9, 2023

 46 Oct 12, 2023
46 Oct 12, 2023
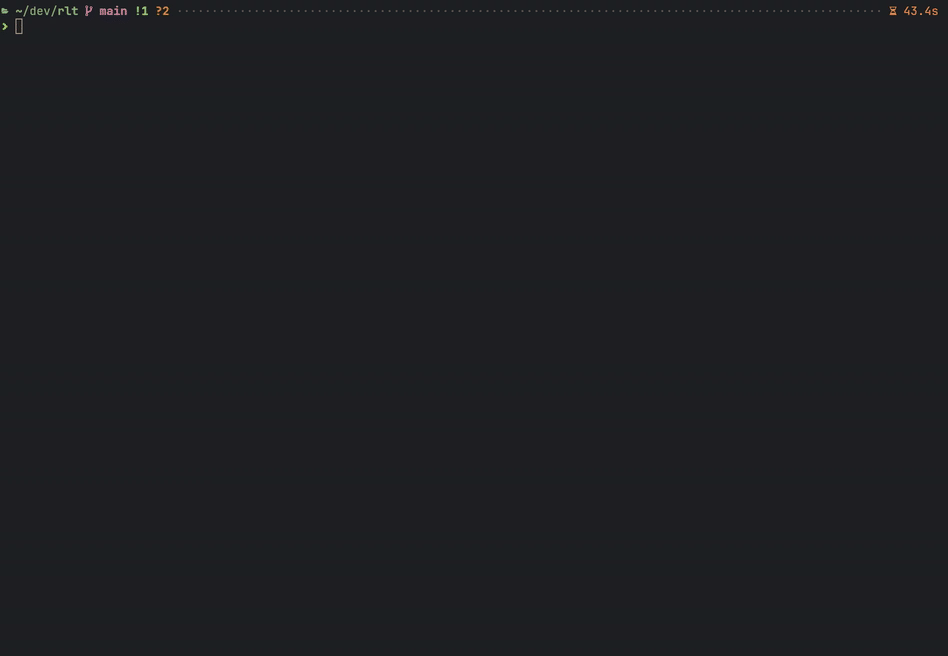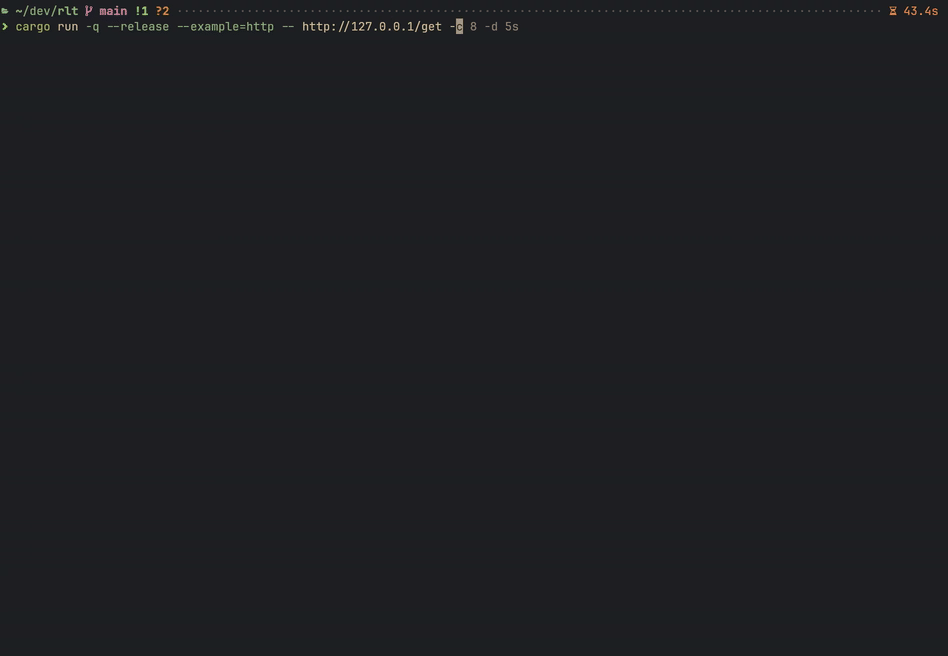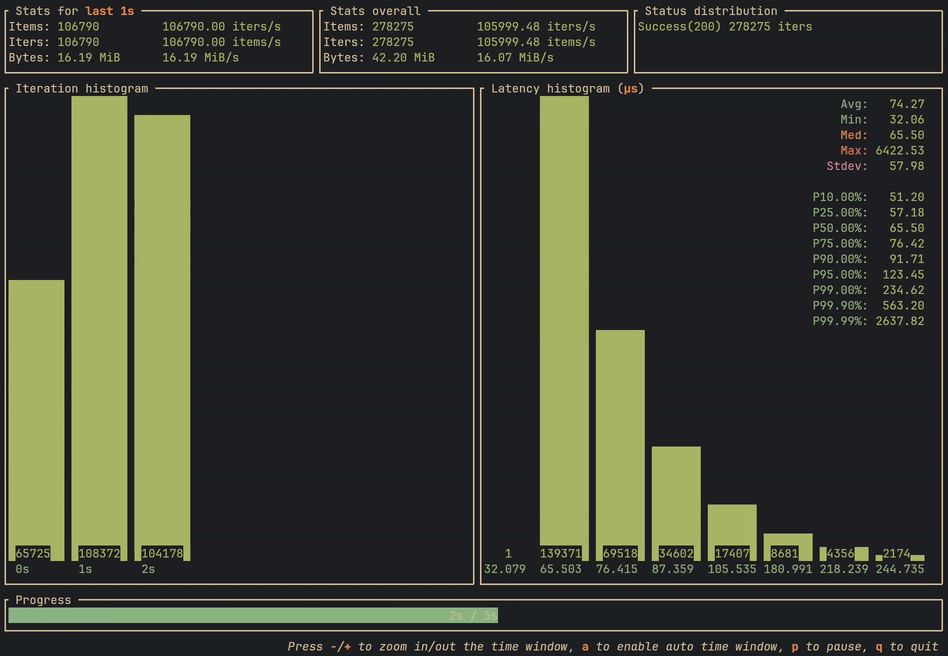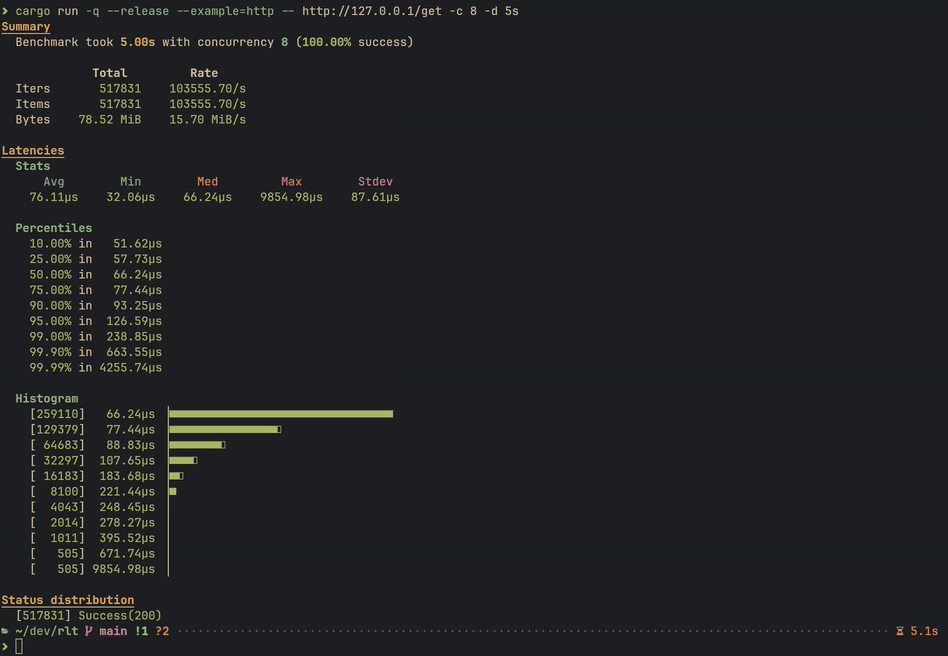
 129 Jul 20, 2024
129 Jul 20, 2024
 107 Dec 6, 2022
107 Dec 6, 2022
 32 Jul 25, 2022
32 Jul 25, 2022
 17.4k Jan 2, 2023
17.4k Jan 2, 2023
 2 Jan 21, 2022
2 Jan 21, 2022
 49 Dec 18, 2022
49 Dec 18, 2022
 2 Sep 4, 2022
2 Sep 4, 2022
 73 Dec 27, 2022
73 Dec 27, 2022
 11 Aug 9, 2022
11 Aug 9, 2022


 12 Dec 6, 2022
12 Dec 6, 2022
 1 Dec 27, 2022
1 Dec 27, 2022
 69 Dec 13, 2022
69 Dec 13, 2022
 36 Jul 5, 2024
36 Jul 5, 2024
 73 Jun 21, 2023
73 Jun 21, 2023
 107 Dec 30, 2022
107 Dec 30, 2022
 430 Dec 29, 2022
430 Dec 29, 2022
 27 Dec 3, 2022
27 Dec 3, 2022
 120 Dec 3, 2022
120 Dec 3, 2022