




What is TensorBase
TensorBase is a new big data warehousing with modern efforts.
TensorBase is building on top of Rust, Apache Arrow and Arrow DataFusion.
TensorBase hopes to change the status quo of bigdata system as follows:
- low efficiency (in the name of 'scalable')
- hard to use (for end users) and understand (for developers)
- not evolving with modern infrastructures (OS, hardware, engineering...)
Features
- Out-of-the-box to play ( get started just now )
- Lighting fast architectural performance in Rust ( real-world benchmarks )
- Modern redesigned columnar storage
- Top performance network transport server
- ClickHouse compatible syntax
- Green installation with DBA-Free ops
- Reliability and high availability (WIP)
- Cluster (WIP)
- Cloud-Native Adaptation (WIP)
- Arrow dataLake (...)
Architecture (in 10,000 meters altitude)
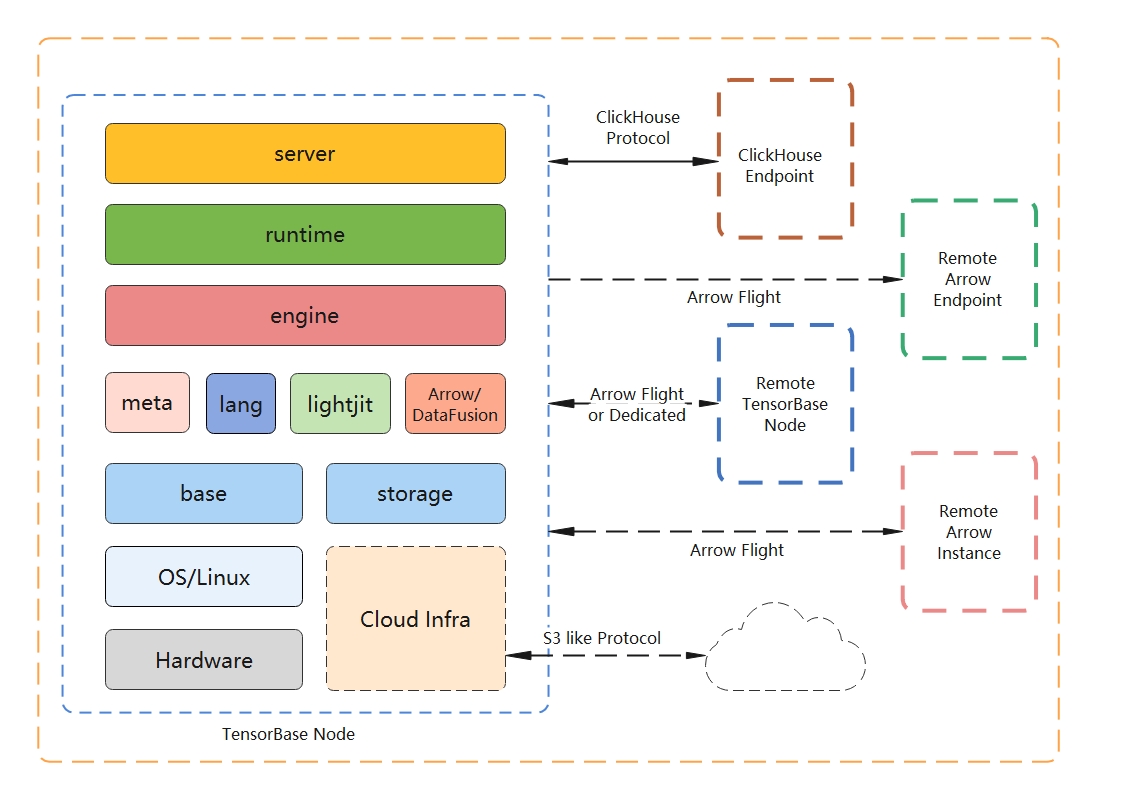
Quick Start

Benchmarks
TensorBase is lighting fast. TensorBase has shown better performance than that of ClickHouse in simple aggregation query on 1.47-billion rows NYC Taxi Dataset.
TensorBase has enabled full workflow for TPC-H benchmarks from data ingestion to query.
More detail about all benchmarks seen in benchmarks.
Roadmap
Community Newsletters
Working Groups
Working Group - Engineering
This is a wg for engineering related topics, like codes or features.
Working Group - Database
This is a higher kind wg for database related topics, like ideas from papers.
Join these working groups on the Discussions or on Discord server.
Communications
Wechat group or other more are on community
Contributing
We have a great contributing guide in the Contributing.
Documents (WIP)
More documents will be prepared soon.
Read the Documents.
License
TensorBase is distributed under the terms of the Apache License (Version 2.0), which is a commercial-friendly open source license.
It is greatly appreciated that,
- you could give this project a star, if you think these got from TensorBase are helpful.
- you could indicate yourself in Who is Using TensorBase, if you are using TensorBase in any project, product or service.
- you could contribute your changes back to TensorBase, if you want your changes could be helpful for more people.
Your encouragements and helps can make more people realize the value of the project, and motivate the developers and contributors of TensorBase to move forward.
See LICENSE for details.



![[Summer 2021] Draft design for MySQL Protocol Server](https://avatars.githubusercontent.com/u/32811268?v=4)








 5k Jan 9, 2023
5k Jan 9, 2023
 184 Dec 22, 2022
184 Dec 22, 2022
 2 Nov 2, 2022
2 Nov 2, 2022
 2.1k Jan 5, 2023
2.1k Jan 5, 2023
 2.9k Dec 28, 2022
2.9k Dec 28, 2022
 12.1k Jan 2, 2023
12.1k Jan 2, 2023
 7.8k Jan 8, 2023
7.8k Jan 8, 2023
 30 Dec 10, 2022
30 Dec 10, 2022
 939 Jan 5, 2023
939 Jan 5, 2023
 172 Dec 23, 2022
172 Dec 23, 2022
 155 Nov 12, 2022
155 Nov 12, 2022
 21 Dec 27, 2022
21 Dec 27, 2022
 2 Sep 26, 2021
2 Sep 26, 2021
 14.4k Jan 8, 2023
14.4k Jan 8, 2023
 0 Oct 29, 2021
0 Oct 29, 2021
 30.7k Jan 7, 2023
30.7k Jan 7, 2023
 40 Dec 20, 2022
40 Dec 20, 2022