![]()
Whatlang
Natural language detection for Rust with focus on simplicity and performance.
![]()
Content
- Features
- Get started
- Documentation
- Supported languages
- Feature toggles
- How does it work?
- Running benchmark
- Comparison with alternatives
- Ports and clones
- Derivation
- License
- Contributors
Features
- Supports 78 languages
- 100% written in Rust
- Lightweight, fast and simple
- Recognizes not only a language, but also a script (Latin, Cyrillic, etc)
- Provides reliability information
Get started
Add to you Cargo.toml:
[dependencies]
whatlang = "0.11.1"
Example:
extern crate whatlang;
use whatlang::{detect, Lang, Script};
fn main() {
let text = "Ĉu vi ne volas eklerni Esperanton? Bonvolu! Estas unu de la plej bonaj aferoj!";
let info = detect(text).unwrap();
assert_eq!(info.lang(), Lang::Epo);
assert_eq!(info.script(), Script::Latin);
assert_eq!(info.confidence(), 1.0);
assert!(info.is_reliable());
}
For more details (e.g. how to blacklist some languages) please check the documentation.
Feature toggles
| Feature | Description |
|---|---|
enum-map |
Lang and Script implement Enum trait from enum-map |
How does it work?
How does the language recognition work?
The algorithm is based on the trigram language models, which is a particular case of n-grams. To understand the idea, please check the original whitepaper Cavnar and Trenkle '94: N-Gram-Based Text Categorization'.
How is_reliable calculated?
It is based on the following factors:
- How many unique trigrams are in the given text
- How big is the difference between the first and the second(not returned) detected languages? This metric is called
ratein the code base.
Therefore, it can be presented as 2d space with threshold functions, that splits it into "Reliable" and "Not reliable" areas. This function is a hyperbola and it looks like the following one:
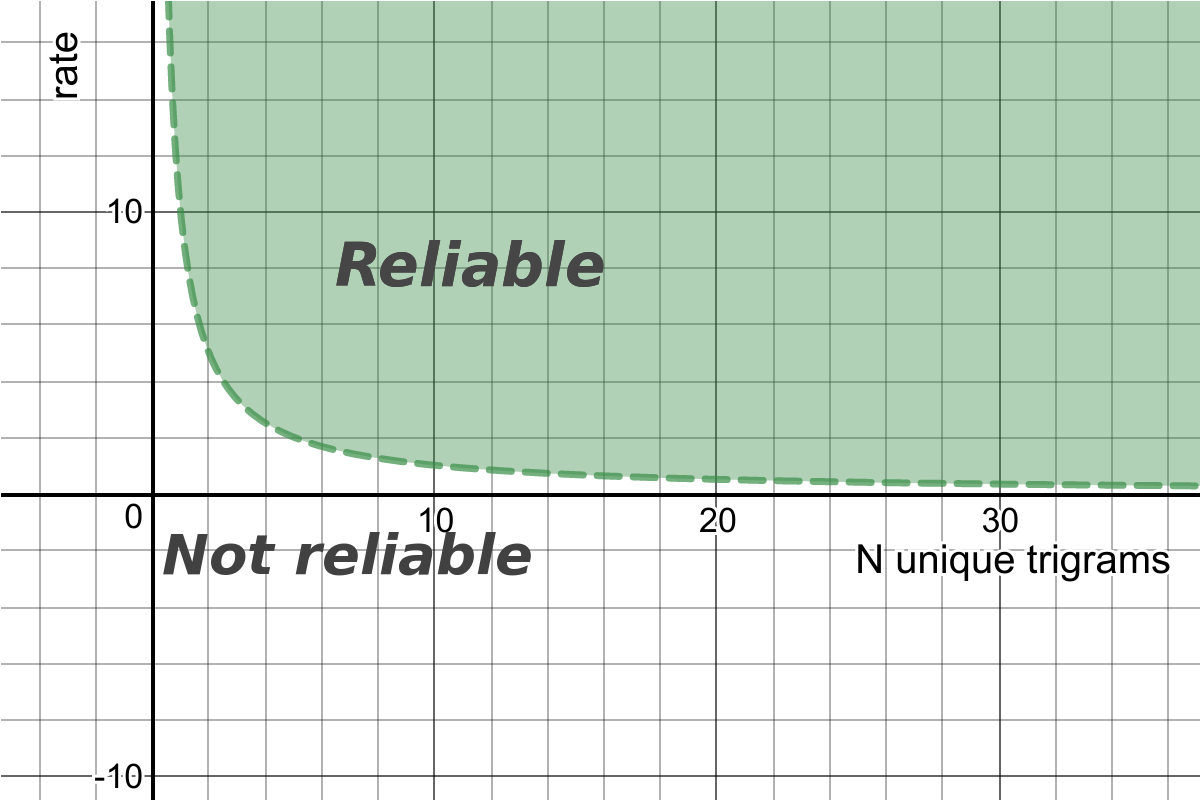
For more details, please check a blog article Introduction to Rust Whatlang Library and Natural Language Identification Algorithms.
Running benchmarks
This is mostly useful to test performance optimizations.
cargo bench
Comparison with alternatives
| Whatlang | CLD2 | CLD3 | |
|---|---|---|---|
| Implementation language | Rust | C++ | C++ |
| Languages | 87 | 83 | 107 |
| Algorithm | trigrams | quadgrams | neural network |
| Supported Encoding | UTF-8 | UTF-8 | ? |
| HTML support | no | yes | ? |
Ports and clones
- whatlang-ffi - C bindings
- whatlanggo - whatlang clone for Go language
- whatlang-py - bindings for Python
- whatlang-rb - bindings for Ruby
Derivation
Whatlang is a derivative work from Franc (JavaScript, MIT) by Titus Wormer.
License
Contributors
- greyblake Potapov Sergey - creator, maintainer.
- Dr-Emann Zachary Dremann - optimization and improvements
- BaptisteGelez Baptiste Gelez - improvements
- Vishesh Chopra - designed the logo

















 7 Dec 30, 2022
7 Dec 30, 2022
 34 Dec 20, 2022
34 Dec 20, 2022
 496 Jan 8, 2023
496 Jan 8, 2023
 211 Dec 28, 2022
211 Dec 28, 2022
 32 Dec 26, 2022
32 Dec 26, 2022
 41 Nov 13, 2022
41 Nov 13, 2022
 25 Apr 28, 2022
25 Apr 28, 2022
 165 Jan 1, 2023
165 Jan 1, 2023
 468 Dec 20, 2022
468 Dec 20, 2022
 356 Dec 24, 2022
356 Dec 24, 2022
 310 Dec 23, 2022
310 Dec 23, 2022
 1k Jan 7, 2023
1k Jan 7, 2023
 13 Oct 31, 2022
13 Oct 31, 2022
 322 Dec 26, 2022
322 Dec 26, 2022
 81 Dec 6, 2022
81 Dec 6, 2022
 72 Dec 16, 2022
72 Dec 16, 2022
 14 Sep 5, 2022
14 Sep 5, 2022
 12 Sep 27, 2022
12 Sep 27, 2022